現在表示しているのは、次のバージョン向けのドキュメントです。Kubernetesバージョン: v1.25
Kubernetes v1.25 のドキュメントは積極的にメンテナンスされていません。現在表示されているバージョンはスナップショットです。最新のドキュメントはこちらです: 最新バージョン
ロギングのアーキテクチャ
アプリケーションログは、アプリケーション内で何が起こっているかを理解するのに役立ちます。ログは、問題のデバッグとクラスターアクティビティの監視に特に役立ちます。最近のほとんどのアプリケーションには、何らかのロギングメカニズムがあります。同様に、コンテナエンジンはロギングをサポートするように設計されています。コンテナ化されたアプリケーションで、最も簡単で最も採用されているロギング方法は、標準出力と標準エラーストリームへの書き込みです。
ただし、コンテナエンジンまたはランタイムによって提供されるネイティブ機能は、たいていの場合、完全なロギングソリューションには十分ではありません。
たとえば、コンテナがクラッシュした場合やPodが削除された場合、またはノードが停止した場合に、アプリケーションのログにアクセスしたい場合があります。
クラスターでは、ノードやPod、またはコンテナに関係なく、ノードに個別のストレージとライフサイクルが必要です。この概念は、クラスターレベルロギング と呼ばれます。
クラスターレベルロギングのアーキテクチャでは、ログを保存、分析、およびクエリするための個別のバックエンドが必要です。Kubernetesは、ログデータ用のネイティブストレージソリューションを提供していません。代わりに、Kubernetesに統合される多くのロギングソリューションがあります。次のセクションでは、ノードでログを処理および保存する方法について説明します。
Kubernetesでの基本的なロギング
この例では、1秒に1回標準出力ストリームにテキストを書き込むコンテナを利用する、Pod specificationを使います。

apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
このPodを実行するには、次のコマンドを使用します:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
出力は次のようになります:
pod/counter created
ログを取得するには、以下のようにkubectl logsコマンドを使用します:
kubectl logs counter
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
コンテナの以前のインスタンスからログを取得するために、kubectl logs --previousを使用できます。Podに複数のコンテナがある場合は、次のように-cフラグでコマンドにコンテナ名を追加することで、アクセスするコンテナのログを指定します。
kubectl logs counter -c count
詳細については、kubectl logsドキュメントを参照してください。
ノードレベルでのロギング
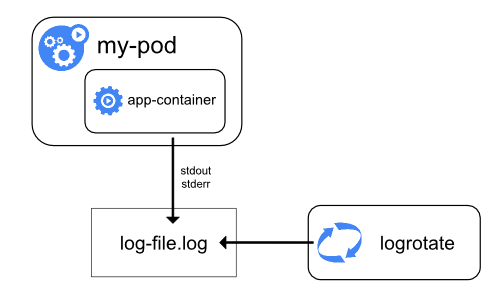
コンテナエンジンは、生成された出力を処理して、コンテナ化されたアプリケーションのstdoutとstderrストリームにリダイレクトします。たとえば、Dockerコンテナエンジンは、これら2つのストリームをロギングドライバーにリダイレクトします。ロギングドライバーは、JSON形式でファイルに書き込むようにKubernetesで設定されています。
デフォルトでは、コンテナが再起動すると、kubeletは1つの終了したコンテナをログとともに保持します。Podがノードから削除されると、対応する全てのコンテナが、ログとともに削除されます。
ノードレベルロギングでの重要な考慮事項は、ノードで使用可能な全てのストレージをログが消費しないように、ログローテーションを実装することです。Kubernetesはログのローテーションを担当しませんが、デプロイツールでそれに対処するソリューションを構築する必要があります。たとえば、kube-up.shスクリプトによってデプロイされたKubernetesクラスターには、1時間ごとに実行するように構成されたlogrotateツールがあります。アプリケーションのログを自動的にローテーションするようにコンテナランタイムを構築することもできます。
例として、configure-helper scriptに対応するスクリプトであるkube-up.shが、どのようにGCPでCOSイメージのロギングを構築しているかについて、詳細な情報を見つけることができます。
CRIコンテナランタイムを使用する場合、kubeletはログのローテーションとログディレクトリ構造の管理を担当します。kubeletはこの情報をCRIコンテナランタイムに送信し、ランタイムはコンテナログを指定された場所に書き込みます。2つのkubeletパラメーター、container-log-max-sizeとcontainer-log-max-filesをkubelet設定ファイルで使うことで、各ログファイルの最大サイズと各コンテナで許可されるファイルの最大数をそれぞれ設定できます。
基本的なロギングの例のように、kubectl logsを実行すると、ノード上のkubeletがリクエストを処理し、ログファイルから直接読み取ります。kubeletはログファイルの内容を返します。
kubectl logsで利用可能になります。例えば、10MBのファイルがある場合、logrotateによるローテーションが実行されると、2つのファイルが存在することになります: 1つはサイズが10MBのファイルで、もう1つは空のファイルです。この例では、kubectl logsは最新のログファイルの内容、つまり空のレスポンスを返します。システムコンポーネントログ
システムコンポーネントには、コンテナ内で実行されるものとコンテナ内で実行されないものの2種類があります。例えば以下のとおりです。
- Kubernetesスケジューラーとkube-proxyはコンテナ内で実行されます。
- kubeletとコンテナランタイムはコンテナ内で実行されません。
systemdを搭載したマシンでは、kubeletとコンテナランタイムがjournaldに書き込みます。systemdが存在しない場合、kubeletとコンテナランタイムはvar/logディレクトリ内の.logファイルに書き込みます。コンテナ内のシステムコンポーネントは、デフォルトのロギングメカニズムを迂回して、常に/var/logディレクトリに書き込みます。それらはklogというロギングライブラリを使用します。これらのコンポーネントのロギングの重大性に関する規則は、development docs on loggingに記載されています。
コンテナログと同様に、/var/logディレクトリ内のシステムコンポーネントログはローテーションする必要があります。kube-up.shスクリプトによって生成されたKubernetesクラスターでは、これらのログは、logrotateツールによって毎日、またはサイズが100MBを超えた時にローテーションされるように設定されています。
クラスターレベルロギングのアーキテクチャ
Kubernetesはクラスターレベルロギングのネイティブソリューションを提供していませんが、検討可能な一般的なアプローチがいくつかあります。ここにいくつかのオプションを示します:
- 全てのノードで実行されるノードレベルのロギングエージェントを使用します。
- アプリケーションのPodにログインするための専用のサイドカーコンテナを含めます。
- アプリケーション内からバックエンドに直接ログを送信します。
ノードロギングエージェントの使用
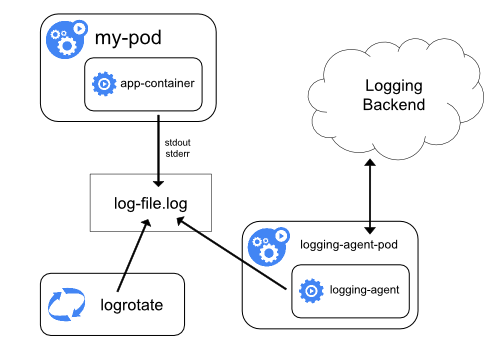
各ノードに ノードレベルのロギングエージェント を含めることで、クラスターレベルロギングを実装できます。ロギングエージェントは、ログを公開したり、ログをバックエンドに送信したりする専用のツールです。通常、ロギングエージェントは、そのノード上の全てのアプリケーションコンテナからのログファイルを含むディレクトリにアクセスできるコンテナです。
ロギングエージェントは全てのノードで実行する必要があるため、エージェントをDaemonSetとして実行することをおすすめします。
ノードレベルのロギングは、ノードごとに1つのエージェントのみを作成し、ノードで実行されているアプリケーションに変更を加える必要はありません。
コンテナはstdoutとstderrに書き込みますが、合意された形式はありません。ノードレベルのエージェントはこれらのログを収集し、集約のために転送します。
ロギングエージェントでサイドカーコンテナを使用する
サイドカーコンテナは、次のいずれかの方法で使用できます:
- サイドカーコンテナは、アプリケーションログを自身の
stdoutにストリーミングします。 - サイドカーコンテナは、アプリケーションコンテナからログを取得するように設定されたロギングエージェントを実行します。
ストリーミングサイドカーコンテナ
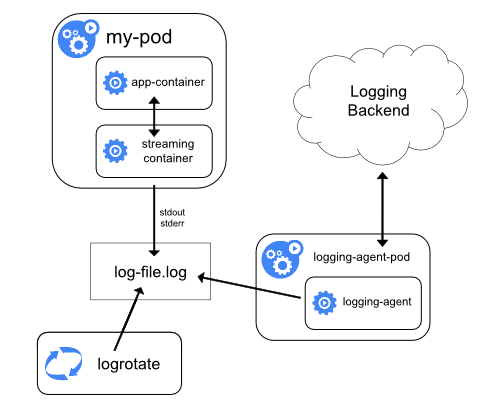
サイドカーコンテナに自身のstdoutやstderrストリームへの書き込みを行わせることで、各ノードですでに実行されているkubeletとロギングエージェントを利用できます。サイドカーコンテナは、ファイル、ソケット、またはjournaldからログを読み取ります。各サイドカーコンテナは、ログを自身のstdoutまたはstderrストリームに出力します。
このアプローチにより、stdoutまたはstderrへの書き込みのサポートが不足している場合も含め、アプリケーションのさまざまな部分からいくつかのログストリームを分離できます。ログのリダイレクトの背後にあるロジックは最小限であるため、大きなオーバーヘッドにはなりません。さらに、stdoutとstderrはkubeletによって処理されるため、kubectl logsのような組み込みツールを使用できます。
たとえば、Podは単一のコンテナを実行し、コンテナは2つの異なる形式を使用して2つの異なるログファイルに書き込みます。Podの構成ファイルは次のとおりです:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
両方のコンポーネントをコンテナのstdoutストリームにリダイレクトできたとしても、異なる形式のログエントリを同じログストリームに書き込むことはおすすめしません。代わりに、2つのサイドカーコンテナを作成できます。各サイドカーコンテナは、共有ボリュームから特定のログファイルを追跡し、ログを自身のstdoutストリームにリダイレクトできます。
2つのサイドカーコンテナを持つPodの構成ファイルは次のとおりです:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
これで、このPodを実行するときに、次のコマンドを実行して、各ログストリームに個別にアクセスできます:
kubectl logs counter count-log-1
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
出力は次のようになります:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
クラスターにインストールされているノードレベルのエージェントは、それ以上の設定を行わなくても、これらのログストリームを自動的に取得します。必要があれば、ソースコンテナに応じてログをパースするようにエージェントを構成できます。
CPUとメモリーの使用量が少ない(CPUの場合は数ミリコアのオーダー、メモリーの場合は数メガバイトのオーダー)にも関わらず、ログをファイルに書き込んでからstdoutにストリーミングすると、ディスクの使用量が2倍になる可能性があることに注意してください。単一のファイルに書き込むアプリケーションがある場合は、ストリーミングサイドカーコンテナアプローチを実装するのではなく、/dev/stdoutを宛先として設定することをおすすめします。
サイドカーコンテナを使用して、アプリケーション自体ではローテーションできないログファイルをローテーションすることもできます。このアプローチの例は、logrotateを定期的に実行する小さなコンテナです。しかし、stdoutとstderrを直接使い、ローテーションと保持のポリシーをkubeletに任せることをおすすめします。
ロギングエージェントを使用したサイドカーコンテナ
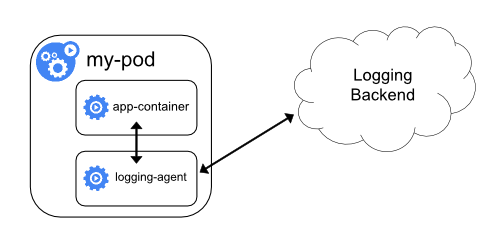
ノードレベルロギングのエージェントが、あなたの状況に必要なだけの柔軟性を備えていない場合は、アプリケーションで実行するように特別に構成した別のロギングエージェントを使用してサイドカーコンテナを作成できます。
kubectl logsを使用してこれらのログにアクセスすることができません。ロギングエージェントを使用したサイドカーコンテナを実装するために使用できる、2つの構成ファイルを次に示します。最初のファイルには、fluentdを設定するためのConfigMapが含まれています。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
2番目のファイルは、fluentdを実行しているサイドカーコンテナを持つPodを示しています。Podは、fluentdが構成データを取得できるボリュームをマウントします。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
サンプル構成では、fluentdを任意のロギングエージェントに置き換えて、アプリケーションコンテナ内の任意のソースから読み取ることができます。
アプリケーションから直接ログを公開する
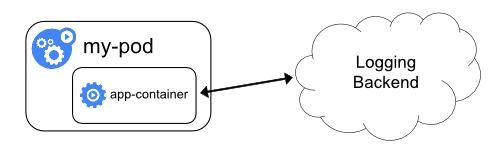
すべてのアプリケーションから直接ログを公開または送信するクラスターロギングは、Kubernetesのスコープ外です。